
高校情報Ⅱ「重回帰分析」
いろいろな事情で、「情報Ⅱ等」を高校で指導する需要は高まっていると思われる。
ただ、どこまでが「情報Ⅰ」で、どこからが「情報Ⅱ」かというのは案外境界が曖昧なところも。
今回は、そうした中で「回帰分析」に着目し、要するに単回帰分析は情報Ⅰ、そこからジャンプして重回帰分析を扱うと情報Ⅱと言えるんじゃない?(つまり、重回帰分析を扱うことで「情報Ⅱ等」を履修したといえるんじゃないの?)という思いでいつもながらマクロ付きExcelシートを作成してみました。
とりあえずワークシート.pdf はこちらから。
ワークシート+Excel.zip はこちらから。
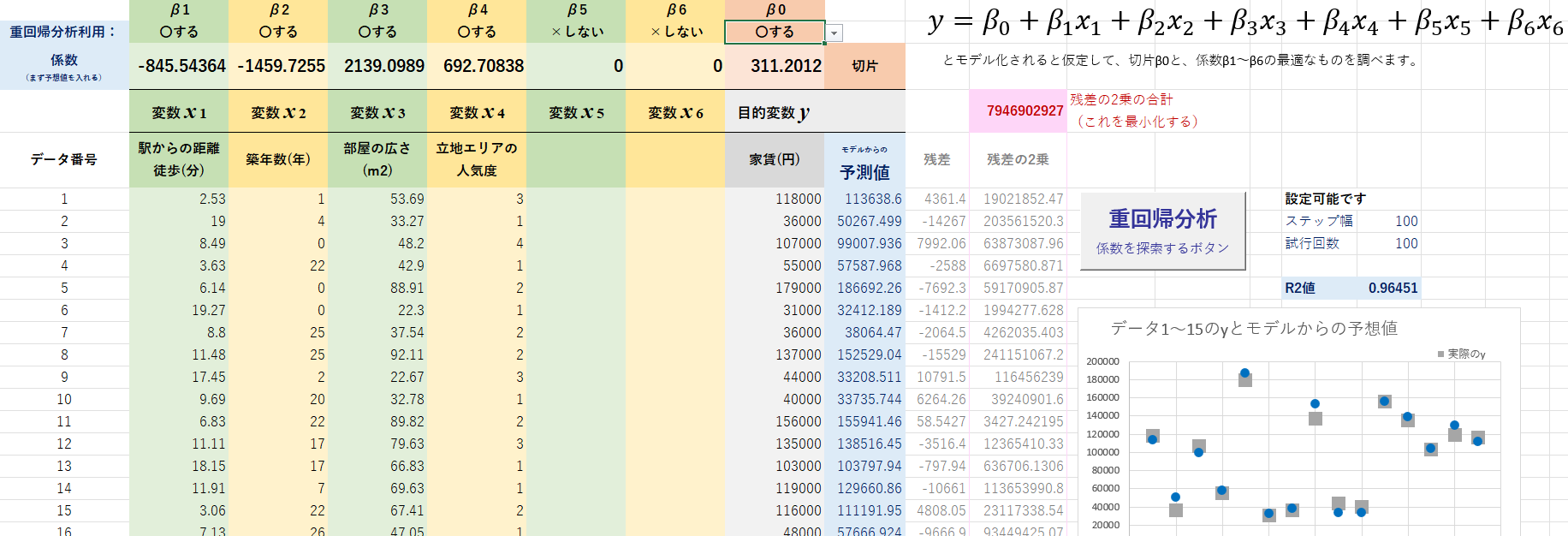
重回帰分析は、Excelのデータ分析アドインで実行可能ではありますが、いきなりドンと結果が出てくるので、原理の理解につながるかというとちょっとブラックボックスなところがある。それぞれの説明変数の係数をランダムで変えていき、ちょっとずつ妥当な値に近づいていく感を体験できるようなものが作れないかということで、作成したもの。
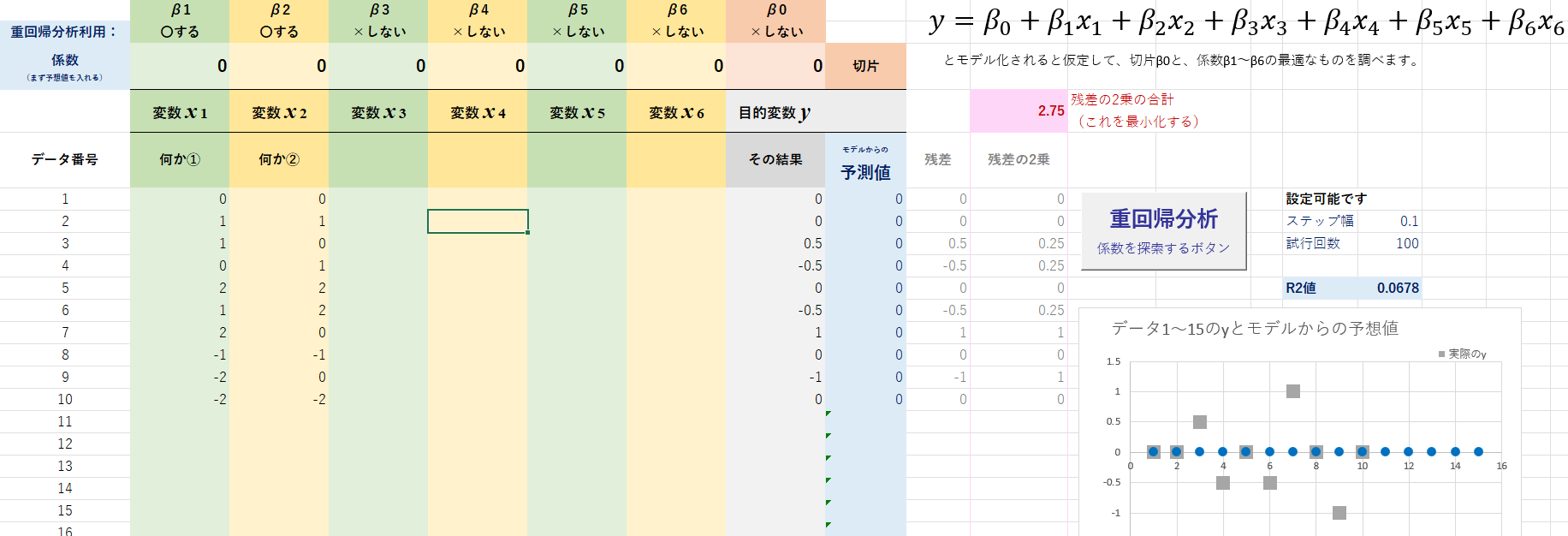
最大100個のデータをもとに、6つの説明変数について、その係数決定を行います。
サンプルデータとして、①何かのデータ ②家賃 ③テストの点数 の3種類のサンプルデータを含みます。②と③は若干の誤差をもって生成した架空のデータです。

話の流れとしては、
①単回帰分析(散布図相関行列)だけを見ていては、本当の関係を見落とすことがあることを導入にしつつ、
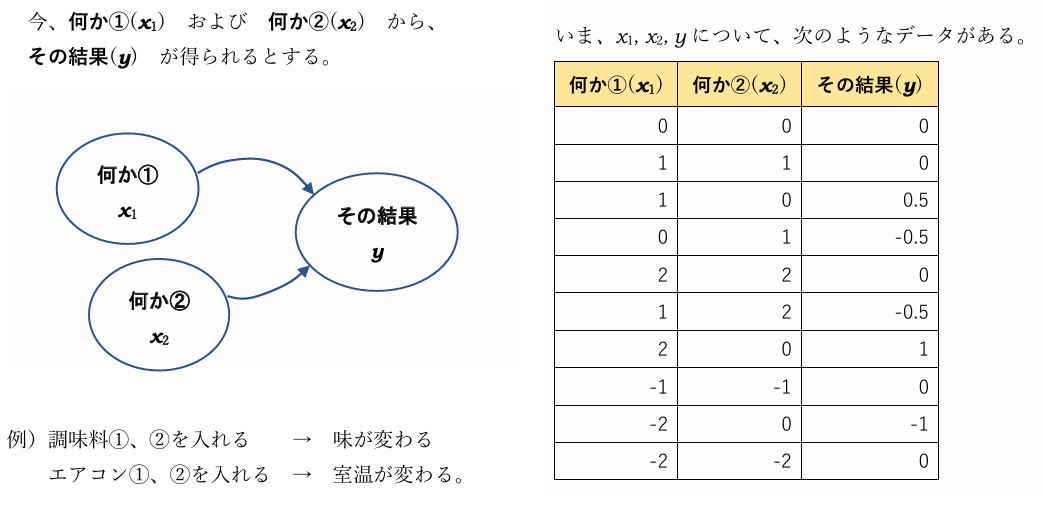
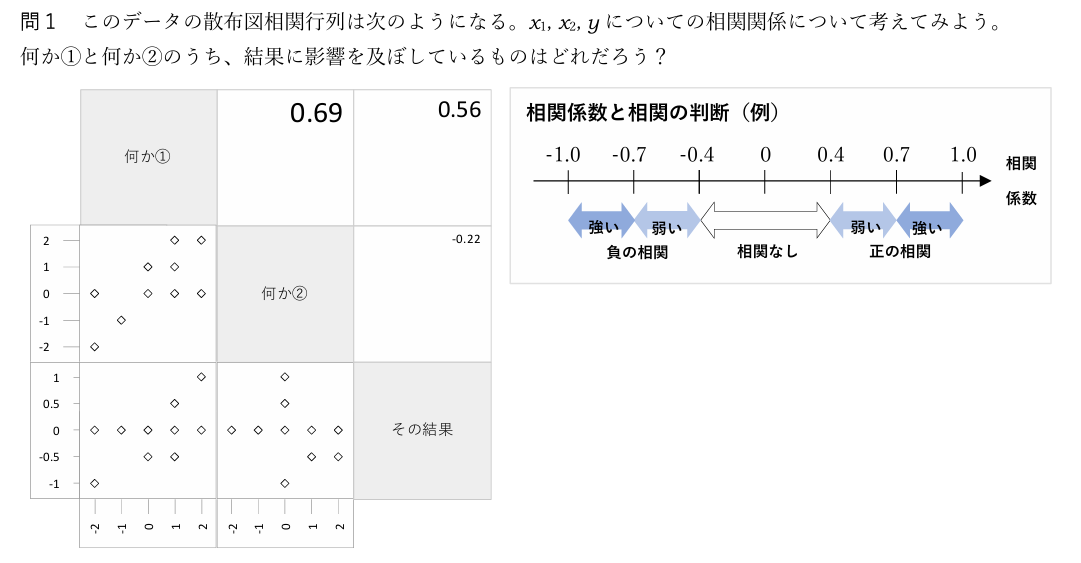
②単回帰分析(散布図相関行列)だと、関係がいま一つわからない「何かのデータ」について、重回帰分析ボタンをぽちっと押すと。
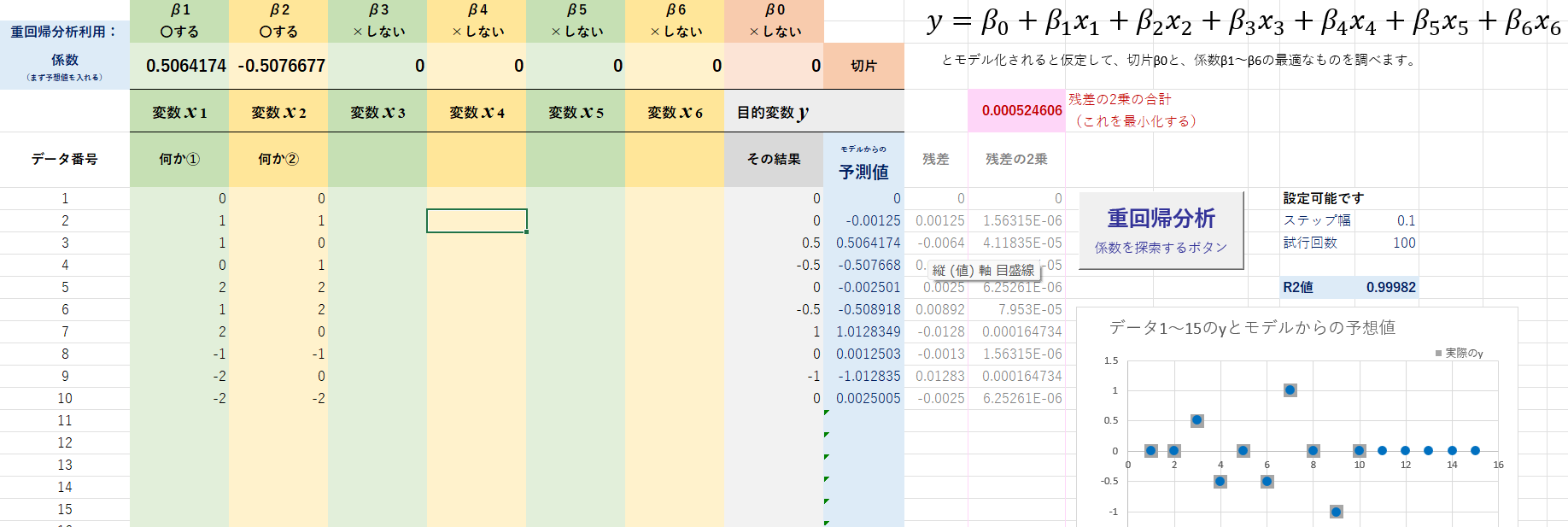 ③それぞれの係数β1とβ2がそれぞれ、0.5と-0.5であることが推定されます。
③それぞれの係数β1とβ2がそれぞれ、0.5と-0.5であることが推定されます。
④サンプルデータを分析してモデルを作成する
繰り返し実行したり、初期値をうまく予想することで、うまくデータを予想できる(R2値の小さい)モデルにたどり着くことができる。
⑤探究等で自分たちで取得したデータについて、分析してみる。(これが大事!)
以上でございます。