
Tf-idfを用いたone-hot表現のコード例
2024/08/06
概要
pythonを使って日本語の文章に対してTf-idfを使ってみる備忘録。Tf-idfについての説明は、wikipedeiaなど他の文献をあたるとして…
対象は、要録所見文のうち、学習に関する所見文。
用いた所見文例.csvはこちらから。(zip化されています)
また、日本語文を単語に区切る分かち書きに際して、Mecabをインストールする必要あり。
インストールの方法は忘れてしまったので、他の文献をあたるとして…(2024年になってまた気が向いたので、Mecabについてはこちらhttps://bibo.capture.jp/memo/mecab)
また、専門用語に関するdicファイルを作って分かち書きしたほうがいい。(たとえば、「授業」+「態度」と分かち書きされるところを「授業態度」とする。)要録所見用.dicファイルはこちらに。
csvファイル→dicファイルという感じで作ったと思われるが、ずいぶん前に作ったので方法を失念。思い出したときに追記しよう。
pythonのコード
import csv
#import pprint
import numpy as np
import MeCab
from sklearn.feature_extraction.text import TfidfVectorizer
#from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
with open(r"C:\Users\******\Desktop\gakusyu_shoken.csv",encoding="utf-8") as f:
reader = csv.reader(f)
l = [row for row in reader]
print(type(l))
arr = np.array(l)
print(type(arr),np.shape(arr))
arr[0,0] = 'index'
arr_1 = arr.T
print(arr_1[1])
wa = MeCab.Tagger ("-Owakati -u C:/Users/******/Desktop/shoken.dic")
#wakatigaki
l_2 = []
l_2.append('index')
#l_2[0] = 'wa_str'
for i in range(916):
l_2.append(wa.parse(arr_1[1][i+1]))
arr_waka_str = np.array(l_2)
#str_1 = wa.parse(arr_1[1][1])
print(l_2)
#tfidf
vectorizer = TfidfVectorizer(use_idf=True)
vecs = vectorizer.fit_transform(arr_waka_str)
for k,v in sorted(vectorizer.vocabulary_.items(), key=lambda x:x[1]): print(k,v)
print(vecs.toarray())
print(np.shape(vecs.toarray()))
plt.imshow(vecs.toarray())
plt.colorbar()
plt.savefig('tfidf_gakusyu.png')
plt.show()
#clusters = KMeans(n_clusters=2, random_state=0).fit_predict(vecs)
#for doc, cls in zip(arr_waka_str, clusters):
# print(cls, doc)
np.savetxt('np_savetxt_gakusyu.csv', vecs.toarray(), fmt="%s", delimiter=",")
アウトプットに関して
for k,v in sorted(vectorizer.vocabulary_.items(), key=lambda x:x[1]): print(k,v)
で、作成した辞書の語彙をprintしています。

1500個余りの単語を語彙として「獲得」していることがわかります。
print(vecs.toarray())と、そのshape
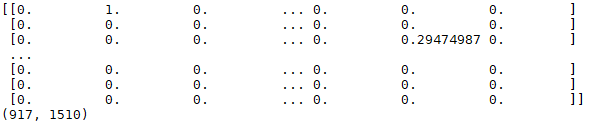 文章が917文あり、その中に1510の単語のうちどれが含まれているかがベクトル化される。二乗和が1になるように正規化されている(多分)。
文章が917文あり、その中に1510の単語のうちどれが含まれているかがベクトル化される。二乗和が1になるように正規化されている(多分)。
図で示すと…
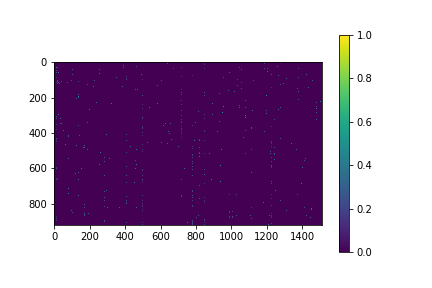 宇宙に散らばる星のように、ポツン、ポツンと単語が含まれる様子。まさに”ohe_hot”という感じ。
宇宙に散らばる星のように、ポツン、ポツンと単語が含まれる様子。まさに”ohe_hot”という感じ。
このベクトルの比較は、意味の類似ではなく、あくまで含まれる語の類似になる。というわけか。
したがって、大学の略称の一致をとるようなタスクに向いていた訳ですな。