
Word2Vecの学習済みmodelを扱う備忘録
2024/02/06
学習した後のモデルを処理する文法を確認するためのコードを貼っておきます。
gensimのword2vecで学習したモデルshoken6.modelを分析します。
pythonのコード
from gensim.models import word2vec
import numpy as np
import matplotlib.pyplot as plt
model = word2vec.Word2Vec.load("./shoken6.model")
print("***********************************")
print(len(model.wv.index2word)) #語彙の数
print(model.wv.vectors.shape) #分散表現の形状
print(model.wv.vectors) #分散表現
print(model.wv.index2word[100:110]) #最初の100番目からの10語
print("***********************************")
print(model.wv.index2word[100], "のベクトル")
print(model.wv.vectors[100]) #100番目の単語のベクトル
print(model.wv.__getitem__("素直")) #"素直"のベクトル
print("***********************************")
"""
#言葉の足し算や引き算は以下の通り
pos = "理科"
neg = "国語"
results = model.wv.most_similar(positive=[pos],negative=[neg])
print ("pos:"+pos,"neg:"+neg)
"""
#1語の場合の類似度の確認
word_0 = '理科'
results = model.wv.most_similar(word_0)
print(word_0, "と類似度の高い単語")
for result in results:
print(result)
print("***********************************")
#"理科"と"化学"の類似度の確認
word_1 = '理科'
word_2 = '化学'
#コサイン類似度は、一般に2つのベクトルから次のように計算します。
a = model.wv.__getitem__(word_1)
b = model.wv.__getitem__(word_2)
cos_sim = np.dot(a, b)/np.linalg.norm(a)/np.linalg.norm(b)
#printの結果は、.most_similarで表示されるものと一致しているはずです
print(word_1, "と", word_2, "のコサイン類似度:", cos_sim)
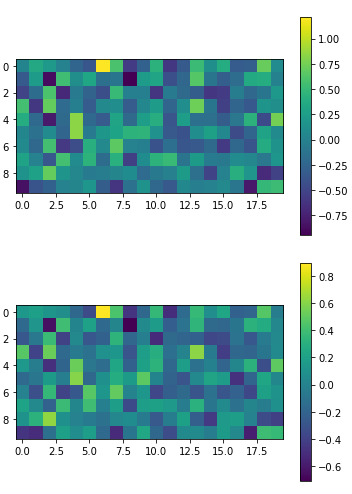
plt.imshow(model.wv.__getitem__(word_1).reshape(10,20))
plt.colorbar()
plt.show()
plt.imshow(model.wv.__getitem__(word_2).reshape(10,20))
plt.colorbar()
plt.show()
plt.imshow(model.wv.__getitem__('素直').reshape(10,20))
plt.colorbar()
plt.show()
アウトプットに関して
print(len(model.wv.index2word)):辞書に登録された単語数
980
print(model.wv.vectors.shape):辞書は980語それぞれに対して200次元
(980, 200)
print(model.wv.vectors):各語のベクトル
[[-0.31556305 0.25042534 -0.30843705 … 0.2533021 -0.04526643
0.02186958]
[ 0.13697276 -0.17418513 -0.03861225 … -0.22277528 0.8458962
-0.01522555]
[-0.31386554 0.0706657 0.5122351 … 0.17934604 -0.07095998
-0.31546038]
…
[ 0.03189972 0.02713368 -0.03583989 … -0.02857453 0.06417285
-0.10585895]
[-0.06771924 0.05249714 0.02783762 … 0.06250255 0.03627604
-0.10140464]
[ 0.03818886 0.08298691 -0.02858759 … 0.08591254 0.168906
0.0820125 ]]
print(model.wv.index2word[100:110]):辞書に登録された単語の確認
[‘素直’, ‘理解’, ‘に対する’, ‘でき’, ‘・’, ‘きちんと’, ‘クラス’, ‘について’, ‘国語’, ‘ため’]
print(model.wv.most_similar(word_0)):類似度の高い語の表示
理科 と類似度の高い単語
(‘化学’, 0.9509211182594299)
(‘生物’, 0.9498825073242188)
(‘英語’, 0.9344501495361328)
(‘地理’, 0.9291201829910278)
(‘物理’, 0.9286836385726929)
(‘数学’, 0.9245099425315857)
(‘国語’, 0.9208290576934814)
(‘分野’, 0.9112943410873413)
(‘特に’, 0.9080013036727905)
(‘現代文’, 0.8767422437667847)
plt.imshow(model.wv.__getitem__(word_1).reshape(10,20))
“理科”(上)と”化学”(下)の図(類似度0.951)
“素直”の図(”理科”との類似度0.552)
