
TensorfFlowの’Hello World’
2020/03/09
TensorfFlow.orgに’Hello World’として紹介されている「MNISTの手書き数字の分類」をやってみる。 備忘録的に注釈をつけ、同じく初心者向けチュートリアルのfashion_mnist分類にあった、「中身のデータのちょっとした確認」を付け加えたもの。
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
#from tensorflow import keras
#訓練データと試験データをダウンロード
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
#各データの各ピクセル0~255を、0~1に
x_train, x_test = x_train / 255.0, x_test / 255.0
#データの確認1
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_train[i], cmap=plt.cm.binary)
plt.xlabel(y_train[i])
plt.show()
#データの確認2(省略)
"""
for i in range(2):
plt.figure()
plt.imshow(x_train[i])
plt.colorbar()
plt.grid(False)
plt.show()
print('ans: ', y_train[i])
"""
model = tf.keras.models.Sequential([
#Flattenは一列にならべること:28*28を784に
tf.keras.layers.Flatten(input_shape=(28, 28)),
#Denseで中間層のノード256個 活性化関数reluを指定
tf.keras.layers.Dense(256, activation='relu'),
#2割のデータを捨て、特定のデータに引きずられないようにする
tf.keras.layers.Dropout(0.2),
#全結合層10個(0~9の分類なので)のノードに 活性化関数softmax
tf.keras.layers.Dense(10, activation='softmax')
])
#adam optimizerを使う、などなど metricsは評価方法
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
#.fitで、10回トレーニング
model.fit(x_train, y_train, epochs=10)
#テスト
#model.evaluate(x_test, y_test)
#予測のテストのチェック
plt.figure()
plt.imshow(x_test[0])
plt.colorbar()
plt.grid(False)
plt.show()
predictions = model.predict(x_test)
print(predictions[0])
print(np.argmax(predictions[0]))
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_test[i], cmap=plt.cm.binary)
plt.xlabel("{} ({:2.0f}%) ans:{}".format(np.argmax(predictions[i]),100*np.max(predictions[i]),y_test[i]))
plt.show()
実行してみますと。
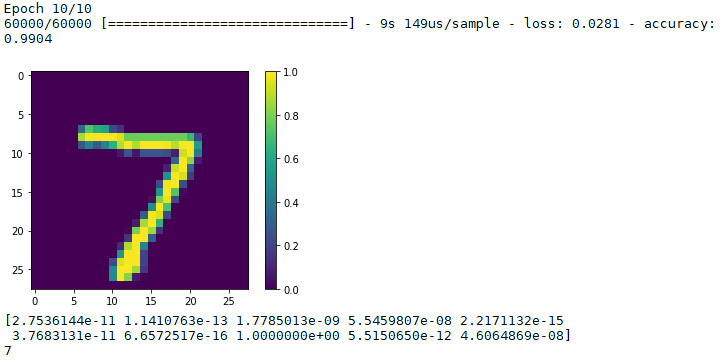 これで、99%くらいの正確さらしい。
これで、99%くらいの正確さらしい。

ちょっと学習が十分すぎる?128ノード、5回くらいで充分かも。ノードや学習回数を減らすと、2行4列目の5を6と区別したり、4行4列目の3を8と区別するあたりに支障をきたす様子でした。
ちなみに、「中間層64ノード、学習1回」での実行結果は…

こんな感じでした。やはり、字はきれいに書くべきですね。