
ベネッセと河合塾の大学コードを対応させる② PythonでN-gram
ベネッセと河合塾の大学コード番号を寄せ、突き合わせたいというところから出発し、Excelでのbi-gramでは十分な精度が得られなかったため、pythonを使ってuni- bi- tri-gramを行い、最も一致率の高いものとマッチングする。
大学コード番号の処理に特化せず、ちょっと汎用性を持たせ、一般的に1列目がindex番号(重複のない番号ならOK)、2列目が文字列、3列目以降がデータとなっている2つのタブ区切りファイル(.tsv)をそれぞれの2列目の文字列の類似度でマッチングし、1つのファイル(match.csv)を作成します。つまり、日本語の揺らぎを許容するリレーショナルツールです。
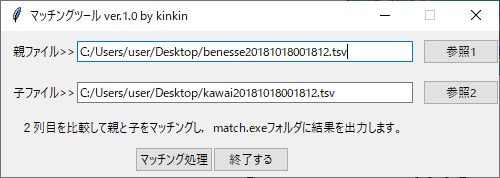
【概要】
make_bene_kawai_tsv.xlsmを使って、(使わなくても良いのだが)読込ファイルを2つ作って…
サンプル(こんな感じのものが出力されます)
benesse_sample.tsv
kawai_sample.tsv
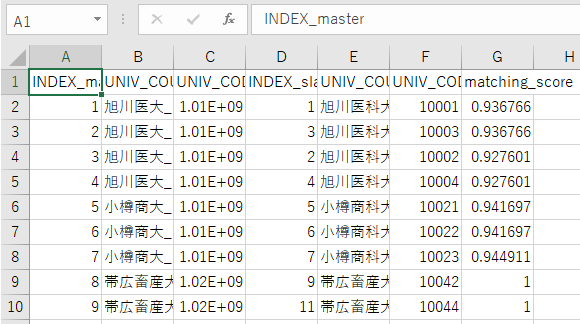
これをマッチングプログラムに読ませまると、1つのファイル(match_(日付).csv)として出力されます。
match201901111622.csv
【マッチングプログラムのpythonコード】
(Anacondaを導入して、Spyderを使うなどして実行してください。)
import sys
from os.path import abspath, dirname
from csv import QUOTE_ALL, QUOTE_NONE
from sklearn.feature_extraction.text import TfidfVectorizer
from pandas import DataFrame, read_table, merge
import unicodedata
from tkinter import Tk, StringVar, LEFT, ttk, filedialog, messagebox
from datetime import datetime
####参照ボタンのイベント
# button1クリック時の処理
def button_master_clicked():
fTyp = [("","*")]
iDir = abspath(dirname(__file__))
filepath_master = filedialog.askopenfilename(filetypes = fTyp,initialdir = iDir)
file_master.set(filepath_master)
def button_slave_clicked():
fTyp = [("","*")]
iDir = abspath(dirname(__file__))
filepath_slave = filedialog.askopenfilename(filetypes = fTyp,initialdir = iDir)
file_slave.set(filepath_slave)
####マッチングの処理
# button4クリック時の処理
def button4_clicked():
path_files = {
"master": file_master.get(),
"slave":file_slave.get()
}
df_master = read_table(path_files["master"], header=0, dtype=str, encoding='Shift_JISx0213', engine="python")
df_slave = read_table(path_files["slave"], header=0, dtype=str, encoding='Shift_JISx0213', engine="python")
df_master = df_master.rename(columns={df_master.columns[0]:"INDEX_master"})
df_slave = df_slave.rename(columns={df_slave.columns[0]:"INDEX_slave"})
# drop empty rows
nan_to_none = lambda v: None if (v is None or v == "nan") else v
df_master["INDEX_master"] = df_master["INDEX_master"].map(nan_to_none)
df_slave["INDEX_slave"] = df_slave["INDEX_slave"].map(nan_to_none)
df_master.dropna(axis=0, subset=["INDEX_master"], inplace=True)
df_slave.dropna(axis=0, subset=["INDEX_slave"], inplace=True)
# convert index into integer
df_master["INDEX_master"] = df_master["INDEX_master"].astype(int)
df_slave["INDEX_slave"] = df_slave["INDEX_slave"].astype(int)
print(file_master.get())
print(file_slave.get())
print('読み込み完了')
# NFKC-normalization, lowercase and fill empty with special token
normalizer = lambda s: unicodedata.normalize("NFKC", s).lower()
for df in [df_master, df_slave]:
for column in df.columns:
df[column] = df[column].map(lambda v: normalizer(v) if isinstance(v, str) else v)
print('# NFKC-normalization完了')
#tup
n_master = df_master.shape[0]
n_slave = df_slave.shape[0]
print("master: %d 個, slave: %d 個" % (n_master, n_slave))
tup_suffix = ("_master","_slave")
#character-ngram function
def ngrams_single(string, n, pad):
if pad and (n > 1):
s_pad = "$"*(n-1)
string = s_pad+string+s_pad
ngrams = zip(*[string[i:] for i in range(n)])
return [''.join(ngram) for ngram in ngrams]
def ngrams(string, lst_n, pad=True):
ret = []
for n in lst_n:
ret.extend(ngrams_single(string, n, pad))
return ret
### instanciate feature extractor: character {uni,bi,tri}-gram
vectorizer = TfidfVectorizer(min_df=1, analyzer=lambda s: ngrams(s, lst_n=[1,2,3]), norm="l2", use_idf=False)
vec_master = df_master.iloc[:,1]
vec_slave = df_slave.iloc[:,1]
#文字unigram/bigram/trigramを適用して,辞書を生成する
vectorizer.fit(vec_master)
vectorizer.fit(vec_slave)
mat_index = vectorizer.transform(vec_master)
mat_query = vectorizer.transform(vec_slave)
#文字列を term-frequency vector に変換する
#文字列を unigram/bigram/trigram に分解
#定義した辞書を用いて,整数列に変換
#整数ごとに集計
#二乗和が1になるように正規化
#find most similar entry
#calculate similarity matrix
mat_sim = mat_query.dot(mat_index.T)
#matching function
#find the best alignment under non-duplicate matching
def match_without_replacement_single(mat_sim, idx_row, idx_col):
# row-major matching
idx_match = mat_sim[idx_row][:,idx_col].argmax(axis=1).A1
T_row = set([(i,idx_col[m]) for i,m in zip(idx_row, idx_match)])
if len(set(idx_match)) == len(idx_row):
return T_row
# column-major matching
idx_match = mat_sim[idx_row][:,idx_col].argmax(axis=0).A1
T_col = set([(idx_row[m],j) for m,j in zip(idx_match, idx_col)])
# merge with two result
T_match = T_row & T_col
return T_match
def match_without_replacement(mat_sim, score=True):
T_match = set()
idx_row = list(range(mat_sim.shape[0]))
idx_col = list(range(mat_sim.shape[1]))
while True:
T_match_t = match_without_replacement_single(mat_sim, idx_row, idx_col)
T_match = T_match | T_match_t
idx_row = [row for row in idx_row if row not in [i for i,j in T_match_t]]
idx_col = [col for col in idx_col if col not in [j for i,j in T_match_t]]
if len(idx_row) == 0 or len(idx_col) == 0:
break
if score:
T_match = [(i,j,mat_sim[i,j]) for i,j in T_match]
return T_match
#execute matching
T_match = match_without_replacement(mat_sim, score=True)
df_match = DataFrame(list(T_match), columns=["idx_slave","idx_master","matching_score"]).sort_values(by="idx_slave").reset_index(drop=True)
assert df_match.shape[0] == df_slave.shape[0]
assert set(df_match["idx_slave"]) == set(range(df_slave.shape[0]))
print(str(df_slave.shape[0]) + ' 個マッチング完了')
#store result
df_slave["INDEX_master"] = df_master.iloc[:,0].values[df_match["idx_master"]]
df_slave["matching_score"] = df_match["matching_score"]
df_result = merge(df_master, df_slave, on="INDEX_master", how="left", suffixes=tup_suffix)
basename = datetime.now().strftime("%Y%m%d%H%M")
# output as csv file(compatible with excel)
df_result.to_csv("./match"+basename+".csv", encoding="Shift_JISx0213", header=True, index=False)
messagebox.showinfo('マッチングツール ver.1.0 by kinkin','match'+basename+'.csvを出力しました。')
########GUIに関する部分
if __name__ == '__main__':
# rootの作成
root = Tk()
root.title('マッチングツール ver.1.0 by kinkin')
root.resizable(False, False)
# Frame1の作成
frame1 = ttk.Frame(root, padding=10)
frame1.grid(row=1)
# ラベルの作成
# 「親ファイル」ラベルの作成
s_master = StringVar()
s_master.set('親ファイル>>')
label1 = ttk.Label(frame1, textvariable=s_master)
label1.grid(row=1, column=1)
# 参照ファイルパス表示ラベル1の作成
file_master = StringVar()
file_master_entry = ttk.Entry(frame1, textvariable=file_master, width=55)
file_master_entry.grid(row=1, column=2)
# 参照ボタン1の作成
button_master = ttk.Button(root, text=u'参照1', command=button_master_clicked)
button_master.grid(row=1, column=3)
# Frame2の作成
frame2 = ttk.Frame(root, padding=10)
frame2.grid(row=2)
# ラベルの作成
# 「子ファイル」ラベルの作成
s_slave = StringVar()
s_slave.set('子ファイル>>')
label3 = ttk.Label(frame2, textvariable=s_slave)
label3.grid(row=1, column=1)
# 参照ファイルパス表示ラベル2の作成
file_slave = StringVar()
file_slave_entry = ttk.Entry(frame2, textvariable=file_slave, width=55)
file_slave_entry.grid(row=1, column=2)
# 参照ボタン2の作成
button_slave = ttk.Button(root, text=u'参照2', command=button_slave_clicked)
button_slave.grid(row=2, column=3)
# Frame3の作成
frame3 = ttk.Frame(root, padding=(10,5))
frame3.grid(row=3)
# ラベルの作成
# 「ファイル」ラベルの作成
s4 = StringVar()
s4.set('2列目を比較して親と子をマッチングし,match.exeフォルダに結果を出力します。')
label4 = ttk.Label(frame3, textvariable=s4)
label4.grid(row=1)
# Frame4の作成
frame4 = ttk.Frame(root, padding=(0,5))
frame4.grid(row=4)
# 処理開始ボタンの作成
button4 = ttk.Button(frame4, text='マッチング処理', command=button4_clicked)
button4.pack(side=LEFT)
# Cancelボタンの作成
button3 = ttk.Button(frame4, text='終了する', command=sys.exit)
button3.pack(side=LEFT)
root.mainloop()
そのうち、codeの解説と、exeファイルを置きたいと思っています。そのうち…。